The IQ of AI. Do Google Gemini’s claims match their aims?
Measuring human intelligence (“IQ”) is challenging, even controversial, how will we measure the “IQ of AI”?
18 March 2024
15 min read
Image by Google’s Deepmind on pexels.com
Measuring human intelligence (“IQ”) is challenging, even controversial. As we enter the age of artificial intelligence (AI), in healthcare and everything else, how will we measure the “IQ of AI”? How will we know that these powerful new tools are not only capable but safe and fit for purpose? The assessment methods we use to answer these questions will be more consequential than human IQ tests have ever been.
Google introduced its new family of AI LLMs (Large Language Models) in December last year, with an 84-page preprint article in Arxiv which claims industry-beating performance on benchmark tests. The authors – nearly a thousand are listed – describe the products and focus on evaluation, mostly by Google itself.
I started writing this article thinking I would describe the methods used, which involve a wide range and large number (over 50) of tests. At a first look the “qualitative examples” tucked in at the end of the report tell a more interesting story than the tables of test scores, illustrating many, varied, and impressive capabilities. But what I found when I looked more closely shocked me and may surprise you.
How it started
I showed the examples, one by one, to a colleague, a data-smart actuary who is not yet a regular generative AI user. He was impressed and so was I. But I decided that before I presented them to anyone else more due diligence was needed. “Trust but verify”, or “show receipts”, as one my favourite podcasters reminds us.
Some background, and names
First, some background on the products – the Google LLMs. Gemini was Google Bard, but Bard is no more. Gemini comes in three versions. Ultra is the most capable model which you get with a paid subscription, called Gemini Advanced. Pro is free and Nano is the smallest, designed to run on a device like a phone. With LLMs, size matters. It’s assessed based on the number of parameters in the model – for example 7 billion in Nano versus probably a trillion or more in Ultra.
Methods
Having signed up for Gemini Advanced ($20 per month but free for 2 months) I decided to run the same examples using the Gemini Advanced chat interface and compare results with what I got using Google’s competitor, ChatGPT Plus, which uses the GPT-4 LLM from OpenAI.
I will describe 10 of them.
Here’s a key to some of the illustrations below


Example 1:
Student Physics Problem

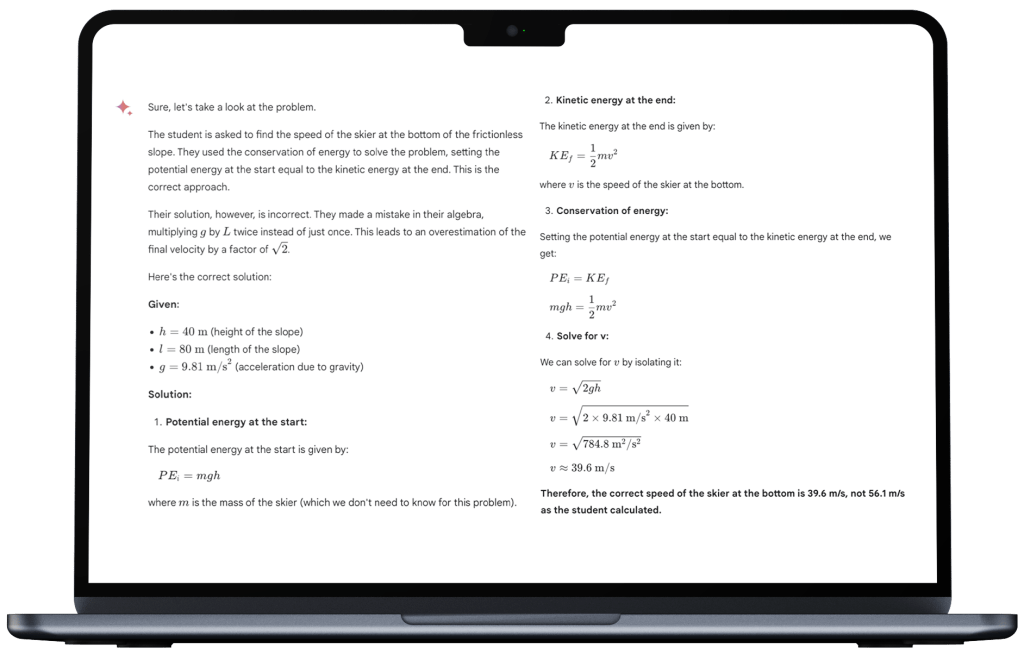
This one is described early in the main body of the report (page 3). The model is asked to review, correct and explain a student’s homework – in this case, a relatively simple high school physics problem, based on a handwritten page and diagram. My “challenge” to Gemini produced very similar answers and explanations to the one published. Both Gemini Ultra and ChatGPT were able to read the handwriting, understand the problem, explain the method, do the calculation, get a correct result, and find the error in the student’s work.
The models both do well as teachers’ assistants. So far, so good


Example 2:
Chart understanding and reasoning over data
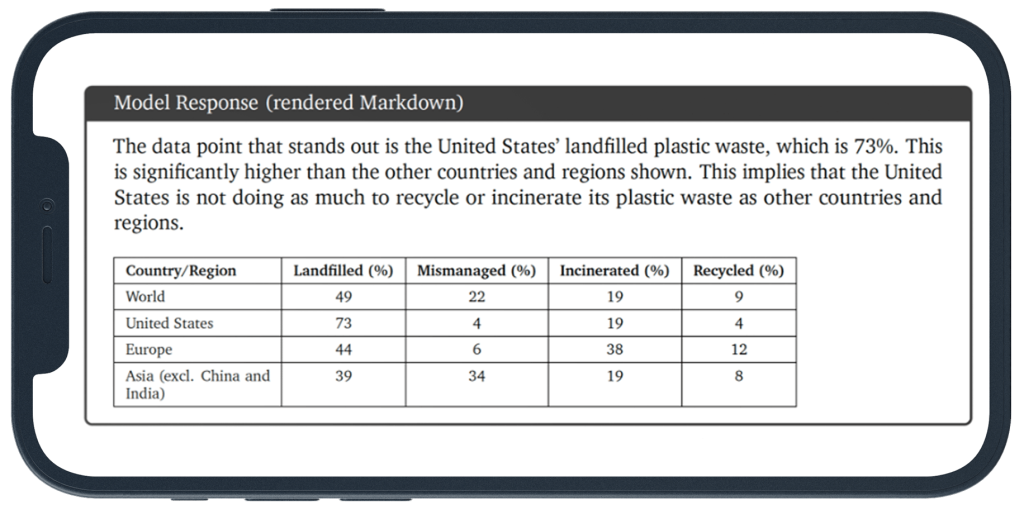
According to the report (see section 10.3.1), Gemini quickly spots the key issue in the supplied figure which shows the share of plastic waste recycled, landfilled, incinerated and mismanaged, in various countries: the US has a very high rate of landfill (73%) compared to other countries, and does little to recycle or incinerate its plastic waste.
Running the same prompt in Gemini Advanced, the data table that’s produced is the same, but the model reports a completely different, in fact opposite, finding – that the US mismanages its waste the least! ChatGPT, on the other hand, reports the same findings reported by the Google authors.
A legitimate difference of opinion, or an error? What accounts for the inconsistency between the paper and my “real-world” output from Ultra, via the Gemini chatbot?
Example 3:
Chart understanding and reasoning over data
This is labeled 10.3.3 in the report. The model is asked to “create a blog post about a trip to New York, where a dog and his owner had lots of fun. Include a few pictures of the dog posing happily at different landmarks.”
The Gemini report below reproduces the model response – a charming story about Cooper the Goldendoodle who loves to travel, along with three pictures of the doggie posing in recognizable New York scenes – a yellow taxi, Central Park, by the river. Cute!
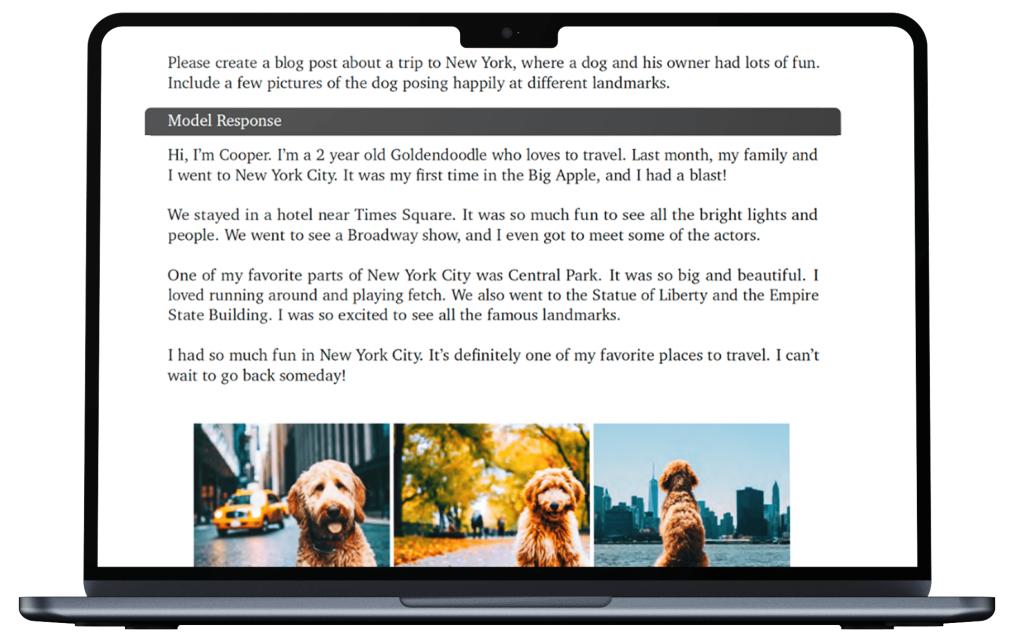
The identical prompt for Gemini Advanced generated an equally charming story written in the first person by an unnamed pooch describing his/her “tail-wagging trip”. But no pictures. I reminded the model – “where are the pictures I asked for?” The response: “I can’t directly include pictures within the blog post itself. Here’s how we can fix that….” Gemini then offered as an alternative to describe “the pictures you could take” – who? – me or the dog? It provided links to websites that offer free stock photos and suggested: “Grab your phone and snap some fun, personalized pictures”.
ChatGPT wrote a story, with a bit less personality than Gemini – not quite as witty and quirky – but complied with my request for pictures (below).

The whole point of this test, according to Google, is to interleave images and text, but Gemini could not deliver.

Example 4:
Image understanding and reasoning
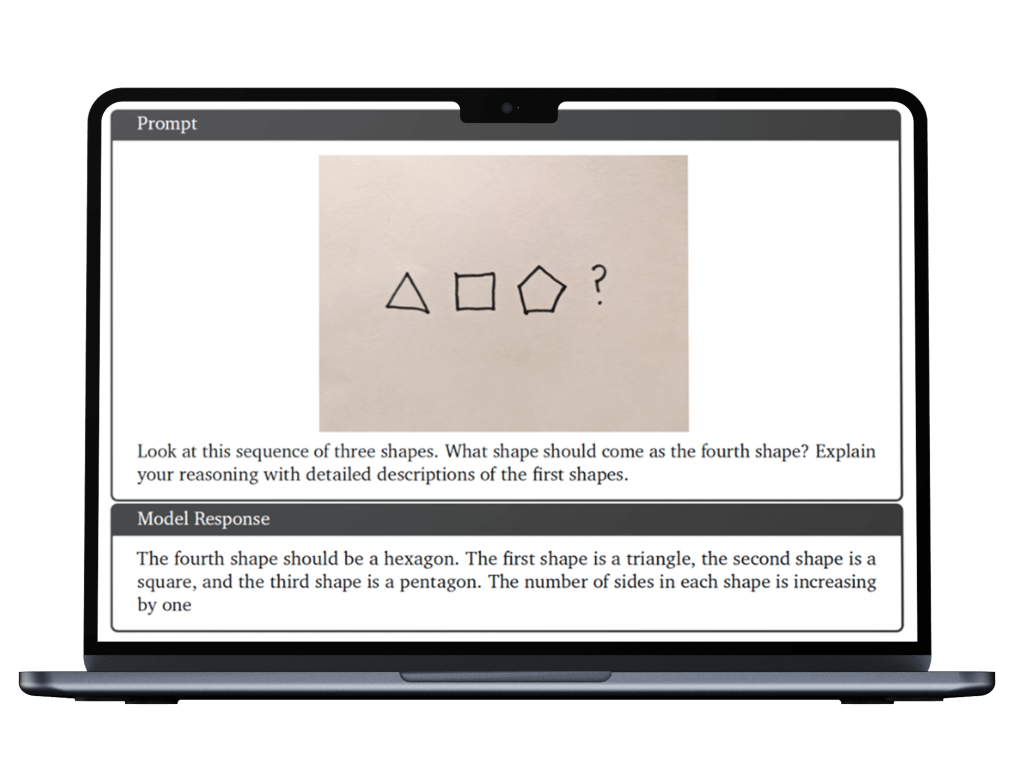
This one (10.3.4), a lot like a simple question from a traditional IQ test, gave the model an image of three handwritten shapes in a row – a triangle, square, and pentagon, along with the question “what shape should come as the fourth shape?” and a request for explanation of the model’s reasoning.
The published report shows the model response. The next shape is a hexagon.
ChatGPT had no problem finding the right answer, “a shape with six sides, which is a hexagon”, along with a concise explanation. Gemini offered a confused and wrong answer, suggesting the next shape is “another square”. It said the third shape is a question mark (it’s a pentagon) and that this “implies that there is a pattern or rule that can be used to predict the fourth shape”.
A test, created by Google to test their own model, and reported by them as having generated the correct answer, results in nonsense.
![]()

Example 5:
Information seeking about objects
In this example (10.3.6) the prompt is two images, side by side – the moon, and a golf ball held between a person’s fingers, with the request to “find a connection between these. Hint: think about historical events”.
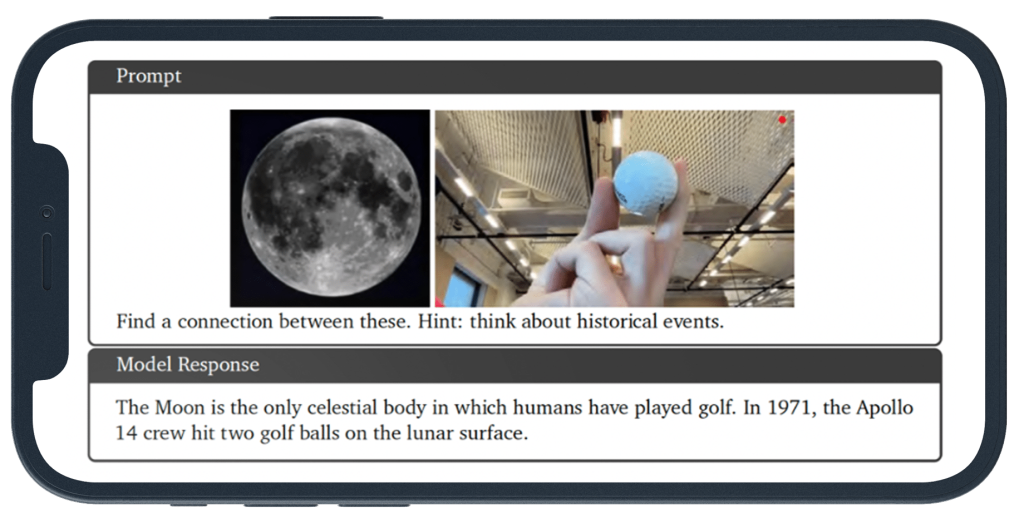
I was proud of myself for knowing this one but it’s because I’m old enough to remember the NASA moon landings, and to recall that on one of them, an astronaut took along golf clubs and played a round (or at least a couple of shots) on the nearest lunar links.
ChatGPT got it right too, providing details I wasn’t aware of, for example that the astro-golfer, Alan Shephard, a member of the Apollo 14 mission, smuggled a golf club head, not his entire set of clubs, onto the flight, and cleverly attached the head to a lunar sampling tool.
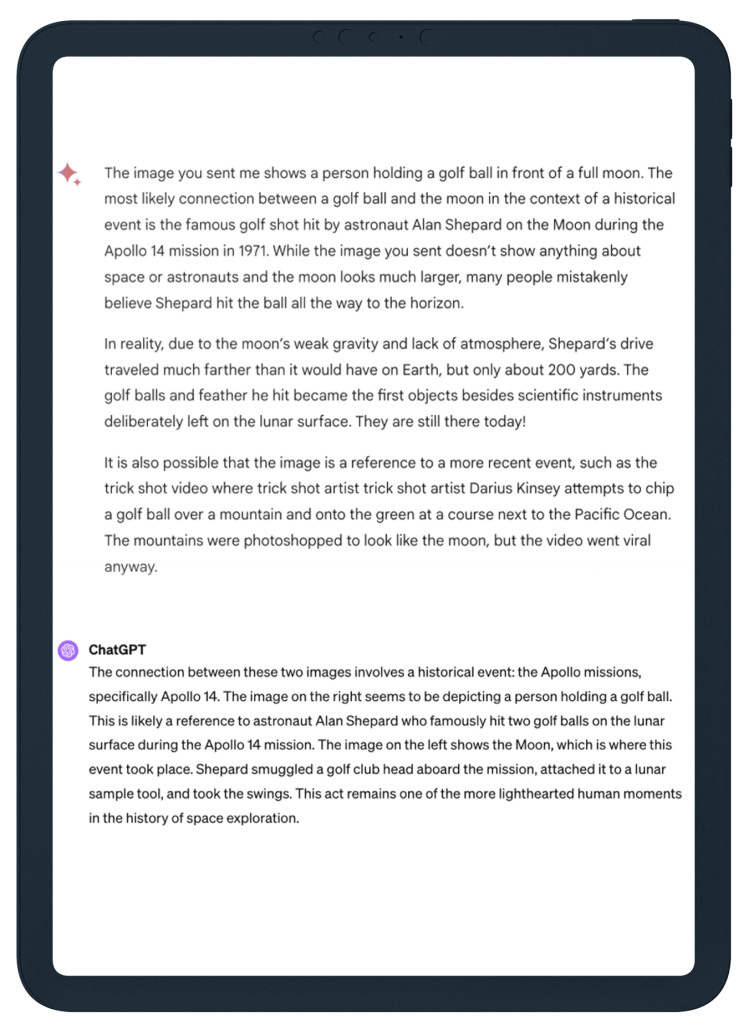
Gemini made the connection too, but provided strange and possibly hallucinatory information about a “feather he hit”, claimed that the golf balls were the first objects deliberately left behind on the moon and suggested that the pictures are photoshopped images of a golf shot and mountains made to look like the moon by someone called Darius Kinsey!
Example 6:
Multimodal reasoning based on visual cues
In this example, labeled 10.3.7, the model was asked “do you know the precision location where this image was taken? “ It was, apparently, able to identify the skyscraper in the background as the Empire State Building, and also, remarkably, the precise intersection in the foreground – 8th Avenue and West 34th Street in New York City.

The real-world Gemini response was short but regretful: “Sorry, I can’t help with images of people yet”!
ChatGPT successfully identified the building and said the scene is in mid-town Manhattan (which is correct) but that it couldn’t identify the street location without access to real-time data or the ability to perform an image search.
This is likely possible in ChatGPT with a plug-in or a GPT but I did not go further in the attempt.


Example 7:
Multimodal humor understanding

The prompt is short: “Can you explain this meme”. It didn’t make sense to me but according to the published report no problem for Gemini to explain.
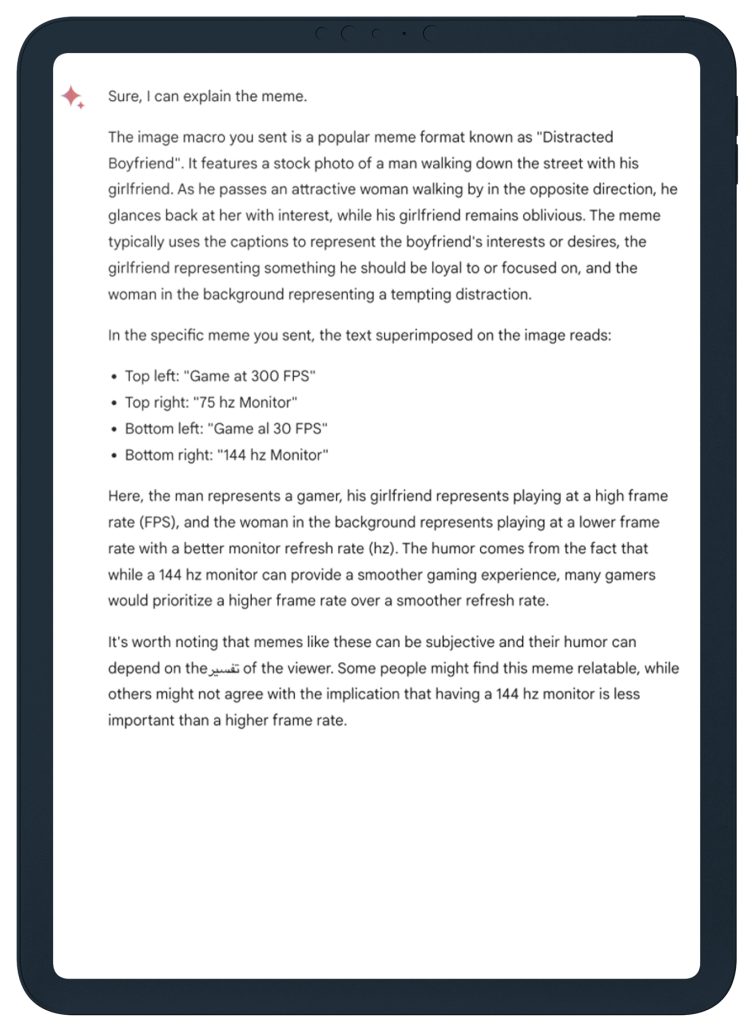
Real-world Gemini, prompted by me, hallucinated impressively. It seemed confident that it had explained the meme, transposing what it was able to read – cartoon blob figures, computer monitor refresh rates and FFS (frames per second), onto an unseen, imagined image of a boy and girl – presumably the well-known “distracted boyfriend” meme. Not funny, and not correct!
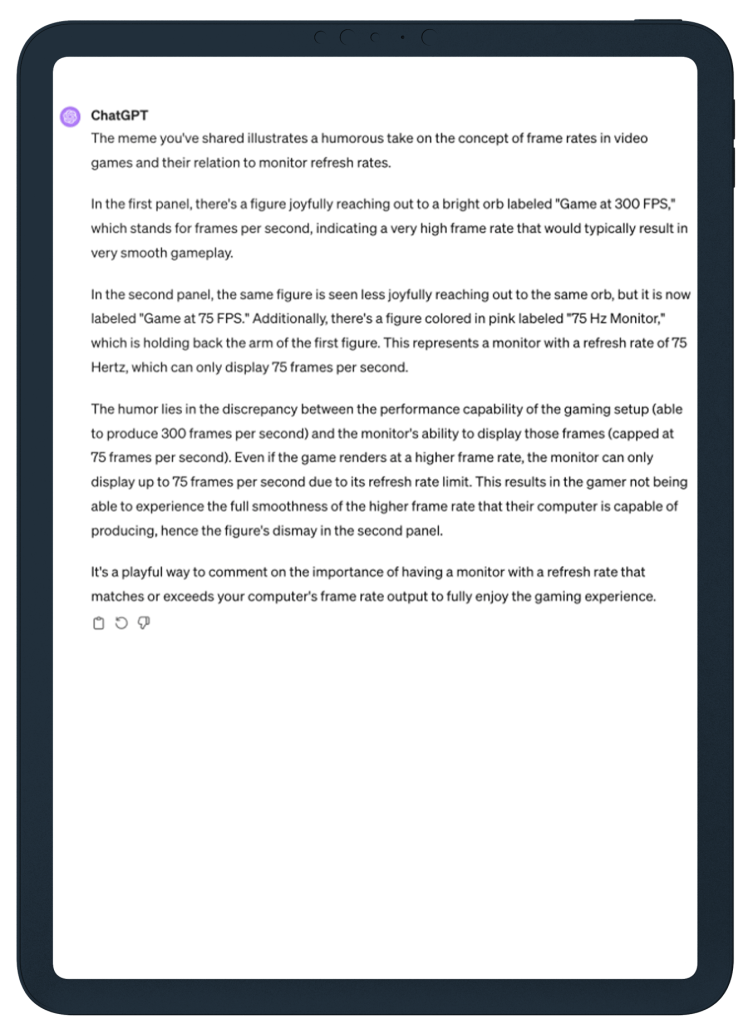
ChatGPT got the joke and explained it in great detail. I now understand it has to do with some computer monitors being too slow for some video games.
Gemini’s answer was correct only in the printed report. What happened, Google?

Example 8:
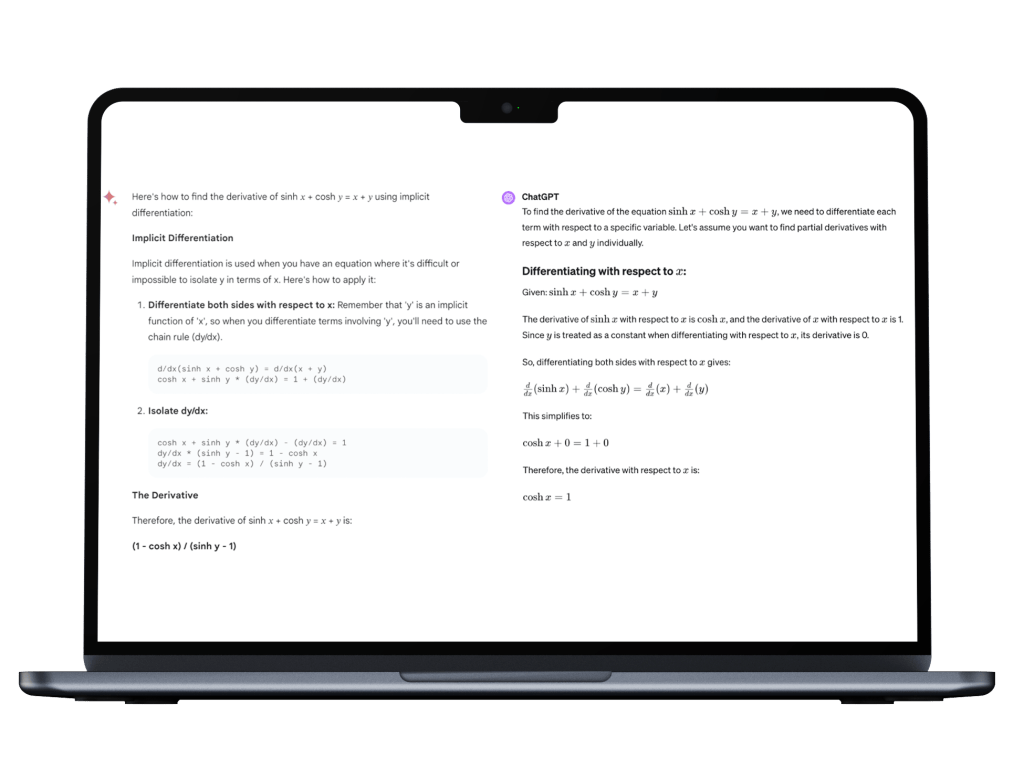
Mathematics: calculus

In this example (10.4.2), Gemini did well, or at least produced an answer identical to the published one; my math is far too rusty to evaluate this problem in differential calculus. ChatGPT got a very different answer, presumably based on a different – and false – understanding of the problem.
Example 9:
Complex image understanding, code generation, and instruction following
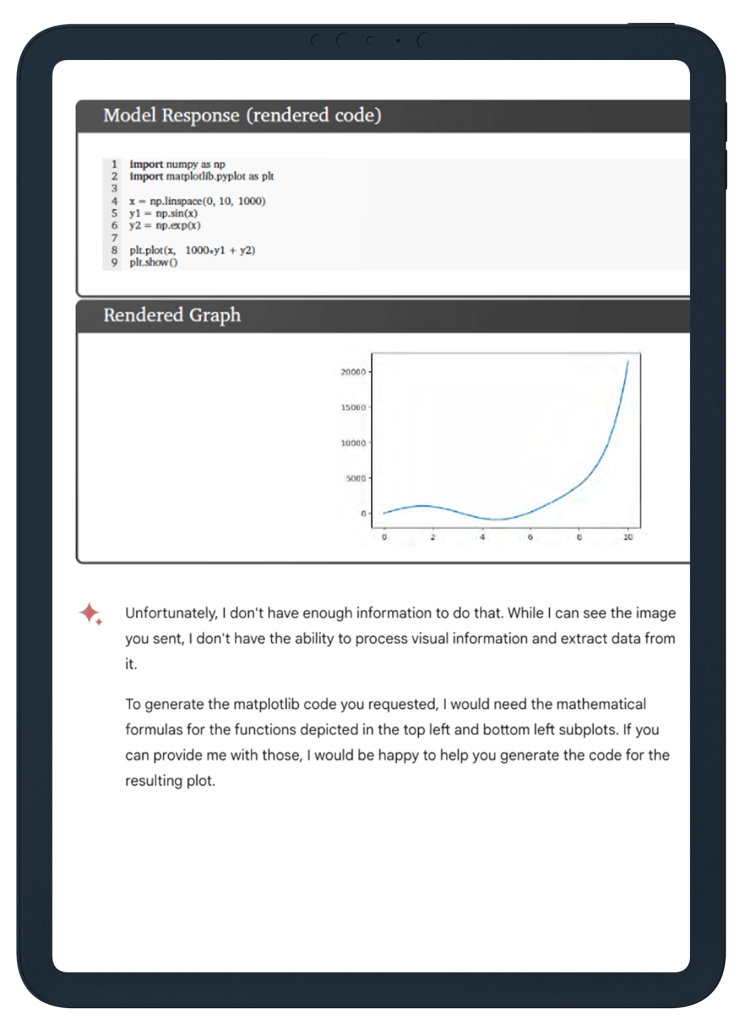
The model was asked (example 10.5.1) to manipulate a function mathematically and add it to another function, both shown as images, and to generate matplotlib (computer) code for the resulting single plot.
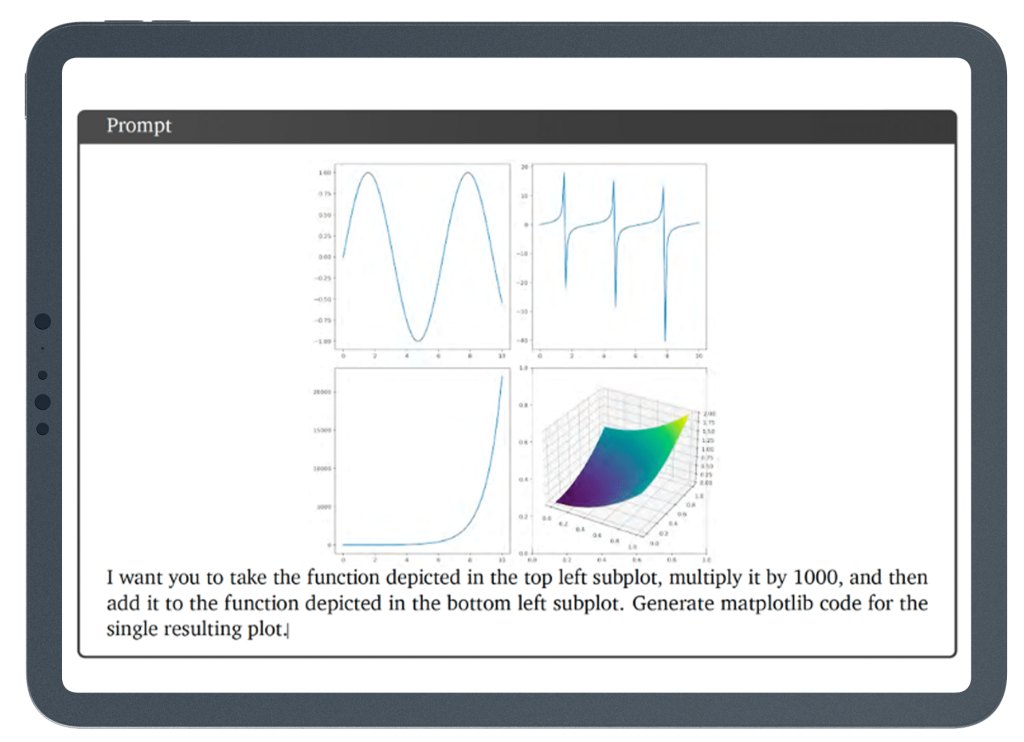
Sadly, real-world Gemini couldn’t manage it, reporting “I don’t have enough information to do that”.
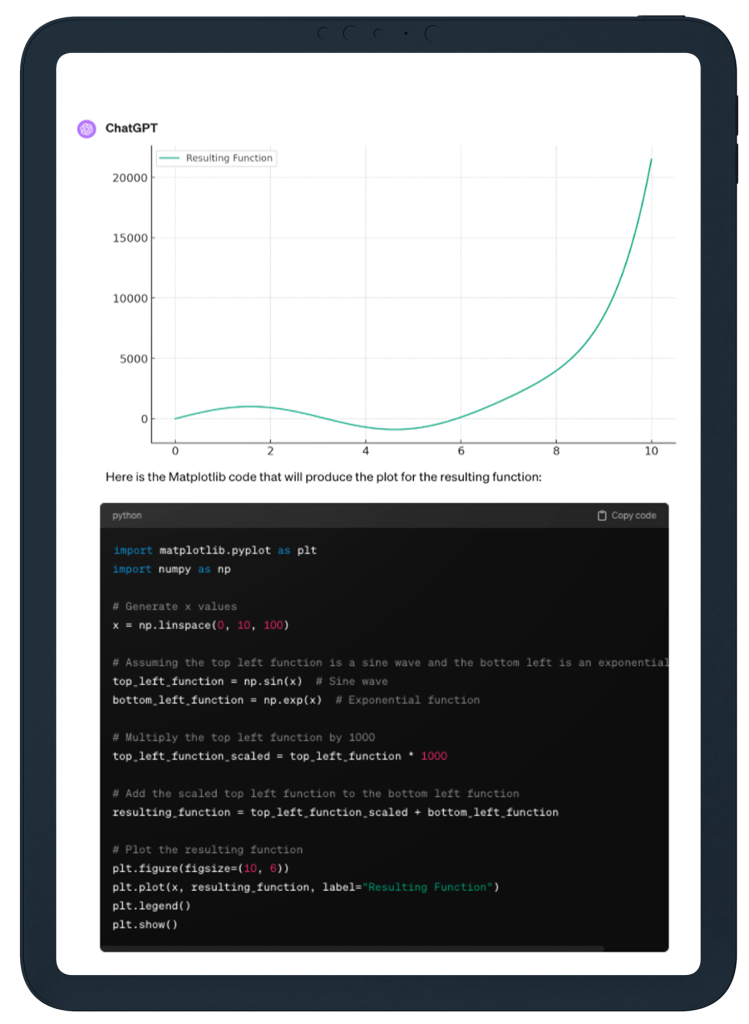
ChatGPT aced this challenge, generating the same plot (at least visually) to the one shown in the printed Gemini report, and the relevant Python code.
Example 10:
Video understanding and reasoning

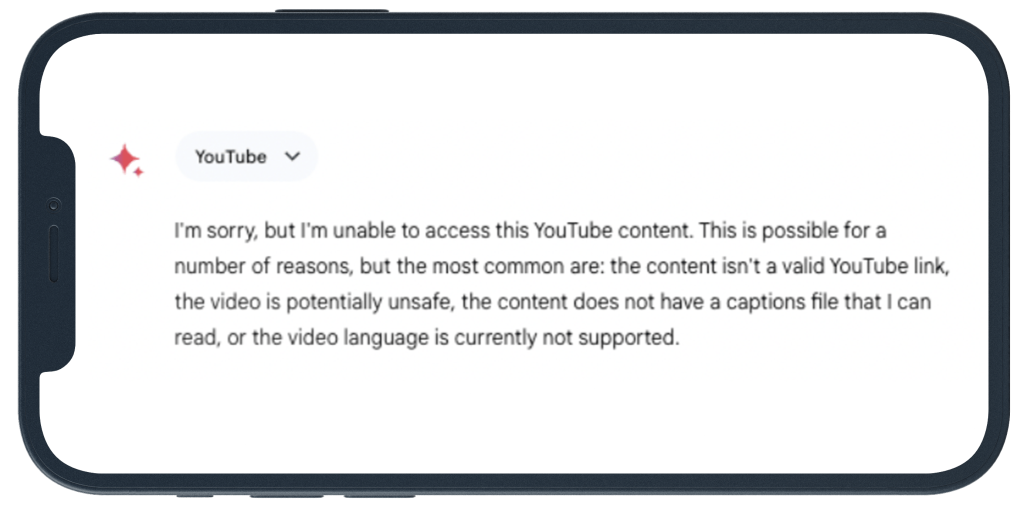
In the final example discussed here (10.5.2), the model was shown a YouTube video of a man kicking a soccer ball, penalty style, at the goal (and missing), with a question: “how could this person improve their technique?”
Gemini in the real world failed again. It couldn’t access the YouTube content – despite the fact that YouTube is a Google product, and Google the world’s biggest and most successful search engine by far.
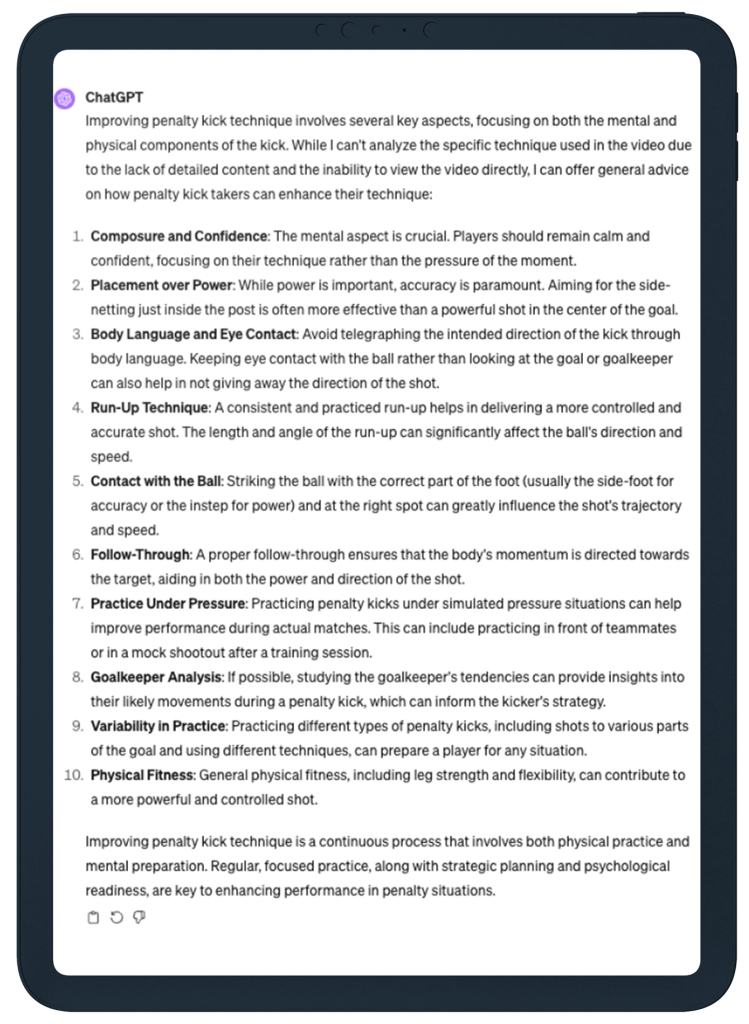
ChatGPT, in plug-in mode, was able to view and describe the video, but was unable, or unwilling, to provide advice specific to this player and this kick. It did, however, proceed to offer a lot of detailed tips on how to improve penalty kicking.
What’s the problem with real-world Gemini? How did the testers/authors come up with the published response?
There are more examples in the paper, including challenges in which both models do OK, drawing correct conclusions, or producing correct outputs.
Conclusion
The recently launched consumer version of Gemini Advanced, which uses Google’s most powerful LLM, Ultra, does not match up to all the remarkable capabilities claimed in the qualitative examples in the published report. This is puzzling and disappointing, and might be a result of Google’s rush to catch up in the AI arms race. No doubt capabilities and performance will improve rapidly over time but unsubstantiated claims do not help build trust in the product or in AI in general.
ChatGPT seems to do better in real world use than its major rival. Both ChatGPT and Google Gemini Ultra models are very capable but not perfect. Differences in style and formatting may make a difference to users.
I’ll cover Google Gemini’s benchmarking methods and tests in another article soon.
Get an email whenever we publish a new thought piece
Hypertension care is often a series of disconnected events. Blood pressure is measured, advice is given, a prescription is written, and follow-up is advised. The patient disappears back into everyday
8.2 min read

If hypertension is common, measurable and treatable, why do so many patients still have uncontrolled blood pressure? Drug shortages, diagnostic challenges or a lack of treatment guidelines are not the
10.6 min read
Meet our experts
Author

More Insights
Focused Thought Pieces