Theory to Therapy: Is AI Ready for Clinical Practice?
Is there enough high-quality evidence that these systems are safe and work well for them to be confidently introduced to the clinic?
03 May 2024
8 min read
Image by ipopba on istockphoto.com
There’s so much excitement about AI (Artificial Intelligence) in healthcare across clinical specialities and locations. However, most recent reports focus on generative AI (ChatGPT, Gemini, and the like) in case scenarios or simulations, not real-world medical practice. Is there enough high-quality evidence that these systems are safe and work well for them to be confidently introduced to the clinic?
All the RCTs (Randomised Controlled Trials)
Last week, Eric Topol and colleagues published their analysis of all randomised trials of AI interventions published between 1 January 2018, and 14 November 2023. These are higher quality studies conducted in actual patient care settings.
How many trials? Which specialities?
Not thousands or even hundreds. Only 86 unique RCTs, including 37 (43%) in gastroenterology, 11 (13%) in radiology, and five (6%) from surgery and cardiology, with 63 (73%) of them published since 2021.
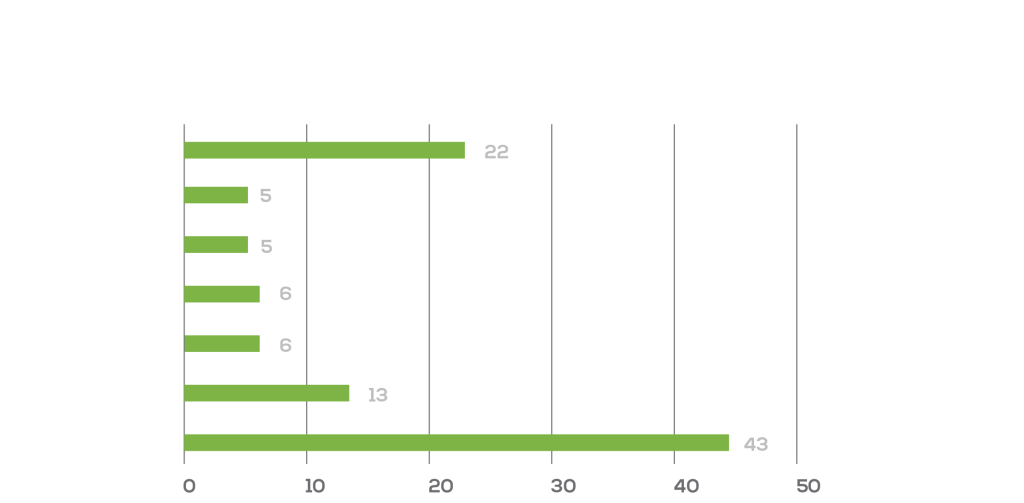
Percentage by speciality of clinical trials in “Randomised controlled trials evaluating artificial intelligence in clinical practice: a scoping review”, Lancet, May 2024.
Where? Who? What?
The US (31%) and China (30%) lead in the number of trials.
Among the most common topics: AI systems for medical imaging, particularly in gastroenterology (which included 81% of the Chinese trials) and radiology.

Encouragingly, most studies (70 [81%] of 86) reported positive “primary end-points” (i.e., outcomes).
These end-points were primarily diagnostic tasks like detection of a colon polyp or an abnormal mammogram, not core clinical outcomes like survival or complication rates.
Most trials came from a single centre and provided few details on demographics, which raises concerns about bias. Also important is that the reported impact on operational efficiency varied, i.e., the AI interventions could either streamline or complicate clinical workflows.
The first AI study with mortality as an end-point
In a study in Nature Medicine published on 29 April, nearly 16,000 patients at two Taiwanese hospitals were randomly chosen to receive an AI alert about each patient’s electrocardiogram (ECG) or to conventional care.
The AI system automatically evaluated the ECG to identify signs that could indicate a high risk of death, determined by a score that combined clinical and ECG features, as shown in the graphs below.
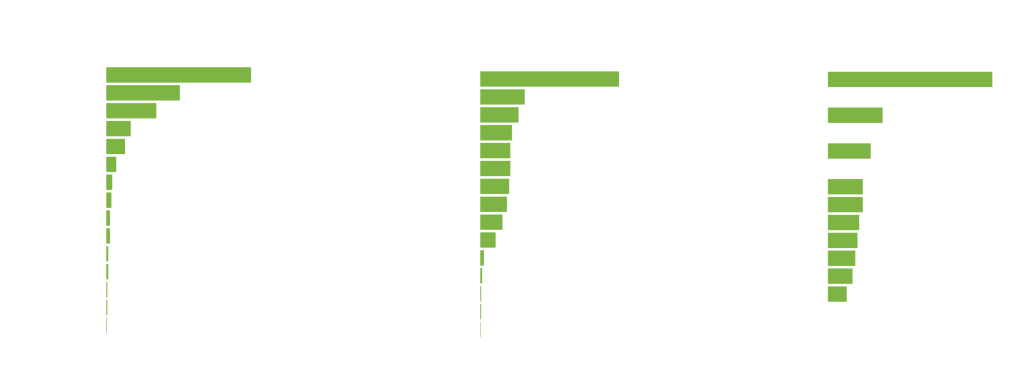
AI-ECG risk predictions based on the integration of patient characteristics and ECG features. Each graph plots relative importance against several different features.
Once the “AI-ECG” identified a high-risk patient, the system generated alert messages sent in real-time to the treating physicians, prompting them to review the AI-generated report along with the patient’s health data and to decide on steps for intensive monitoring or care.
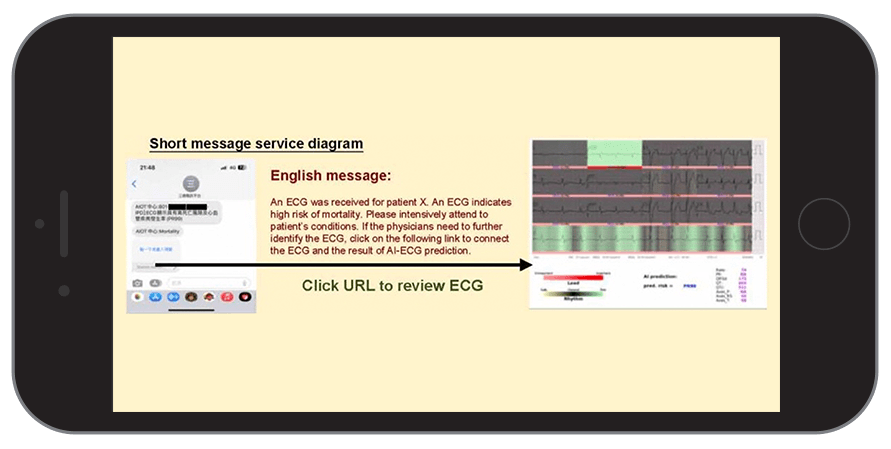
SMS sent to the attending physician
In terms of its selected aim – to see if an AI-based intervention could reduce hospital mortality – this study is a first.

Results?
In these two hospitals, the AI-ECG turned out to be an effective intervention: 3.6% of patients in the intervention group died within 90 days, compared to 4.3% in the control group, a statistically significant 17% reduction of all-cause mortality (hazard ratio (HR) = 0.83, 95% confidence interval (CI) = 0.70 –0.99).
Almost all the benefits were in the high-risk ECG group: a 31% reduction of deaths, saving seven per 100 lives. This is astonishingly good, on par with some of the most effective existing medical treatments.
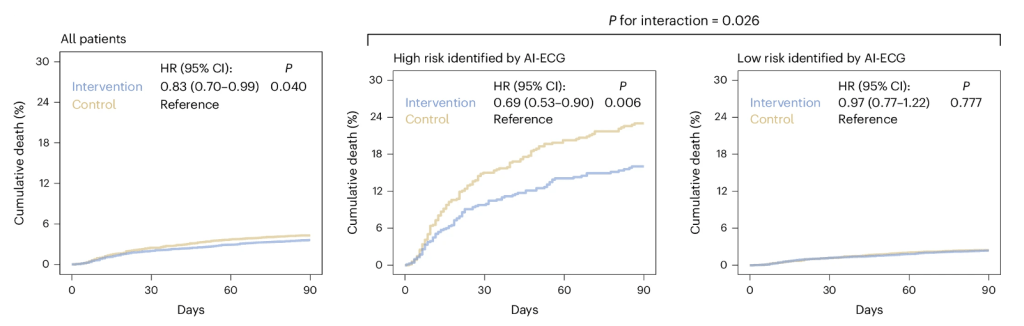
The survival graphs shows a 17% reduction in mortality (cumulative deaths) in the intervention group vs control; 31% in the group identified by AI as high-risk.
Still limitations
Is the AI-ECG ready for implementation in other hospitals? And the other AI systems with positive results in Topol’s review? Maybe not so fast.
In terms of the AI-ECG study, limitations include
- Single blinding means physicians (but not patients) were aware of the study allocation group, triggering them to provide patients with a higher level of care; this could improve outcomes in relation to other patients regardless of whether underlying higher risk is truly present.
- Alert fatigue can diminish effectiveness; the success of interventions like this one relies heavily on how physicians respond to the alerts.
- Potential bias; AI models, including those used for ECG analysis, depend on the data they are trained on to adequately represent other target populations. Predictions might therefore not be accurate or applicable to other patient groups, for example in South African hospitals.
- Transparency and explainability. How AI tools make their recommendations can be complex or even impossible to explain and communicate. In the AI-ECG study, the precise mechanism of benefit for reduction of mortality was not identified.

Negative Trials
While positive findings are encouraging, we have to remember that publication bias is ever present (i.e., negative results are less likely to be published). A Substack article discusses four recent studies that did get into print despite the risk of publication bias:
- Over 2,000 oncology questions were presented to five generative AI models, and only one of them reached the previously established human performance benchmark (>50%) (GPT-4). All had significant error rates.’
- A small randomised study assessed whether generative AI could reduce writing time replying to patient messages. It did not. Longer messages took much longer to read, though physicians did appreciate their “empathic tone”.
- Generative AI for automated medical coding should be an optimal use for AI, but all studied models performed poorly (GPT-4 was best) on 7,600 diagnostic codes (ICD-9) and 3,600 procedure (CPT) codes.
- A simulation study of LLM responses to patient messages about cancer care compared manually composed messages to LLM and LLM-assisted messages. The assessing physicians felt that the LLM drafts risked severe harm in 11 (7·1%) and death in one (0·6%) of 156 survey responses.
More coming
It’s early days. Much more research is underway – or already in print. I used the Topol paper’s Pubmed search methods to look for similar papers (i.e., randomised clinical trials) published since 15 November 2023. I found 37 more download here. I also browsed publications in a new journal – NEJM AI (Table 1 below).
Final thoughts
AI systems are complex interventions that are more difficult to study than medicines, but regulators, administrators, and professionals will increasingly require proof from high quality randomised trials.
It’s exciting to see a reduction in mortality in a large, real-world trial, but it’s also important to critically evaluate whether LLMs are ready for medical practice.
Better reporting standards are needed. The 2020 CONSORT-AI reporting guidelines for clinical trials assessing AI interventions were cited by only 19% of publications.
There are concerns about the generalisability of results and the practicalities of implementation and a need for more multi-centre trials with diverse and patient-relevant outcome measures.
Affordability would be nice, too so less resourced hospitals, countries and regions can enjoy the potential benefits of evidence-based AI interventions in healthcare.
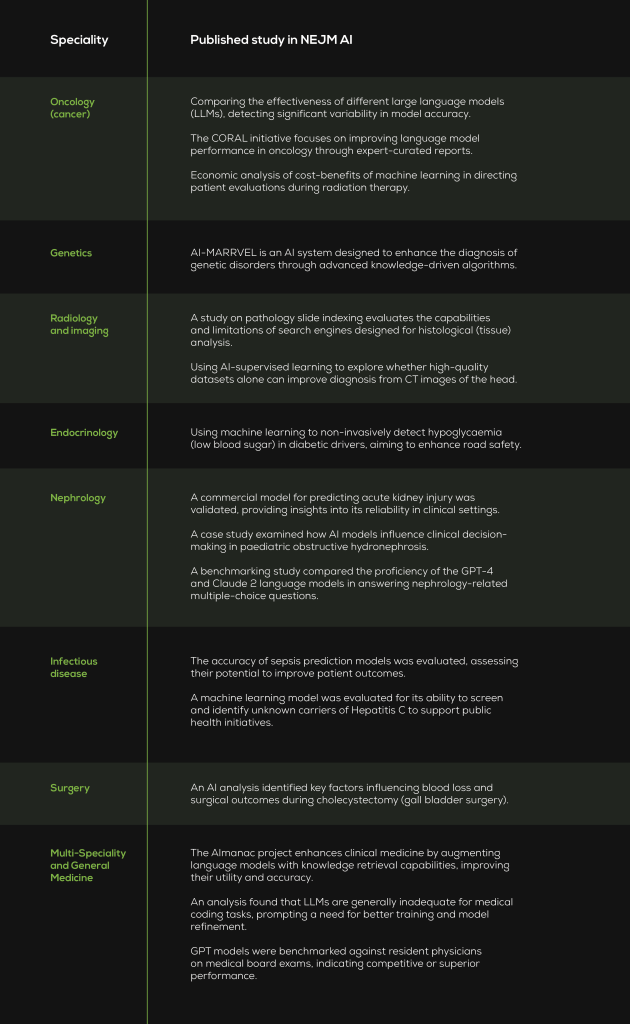
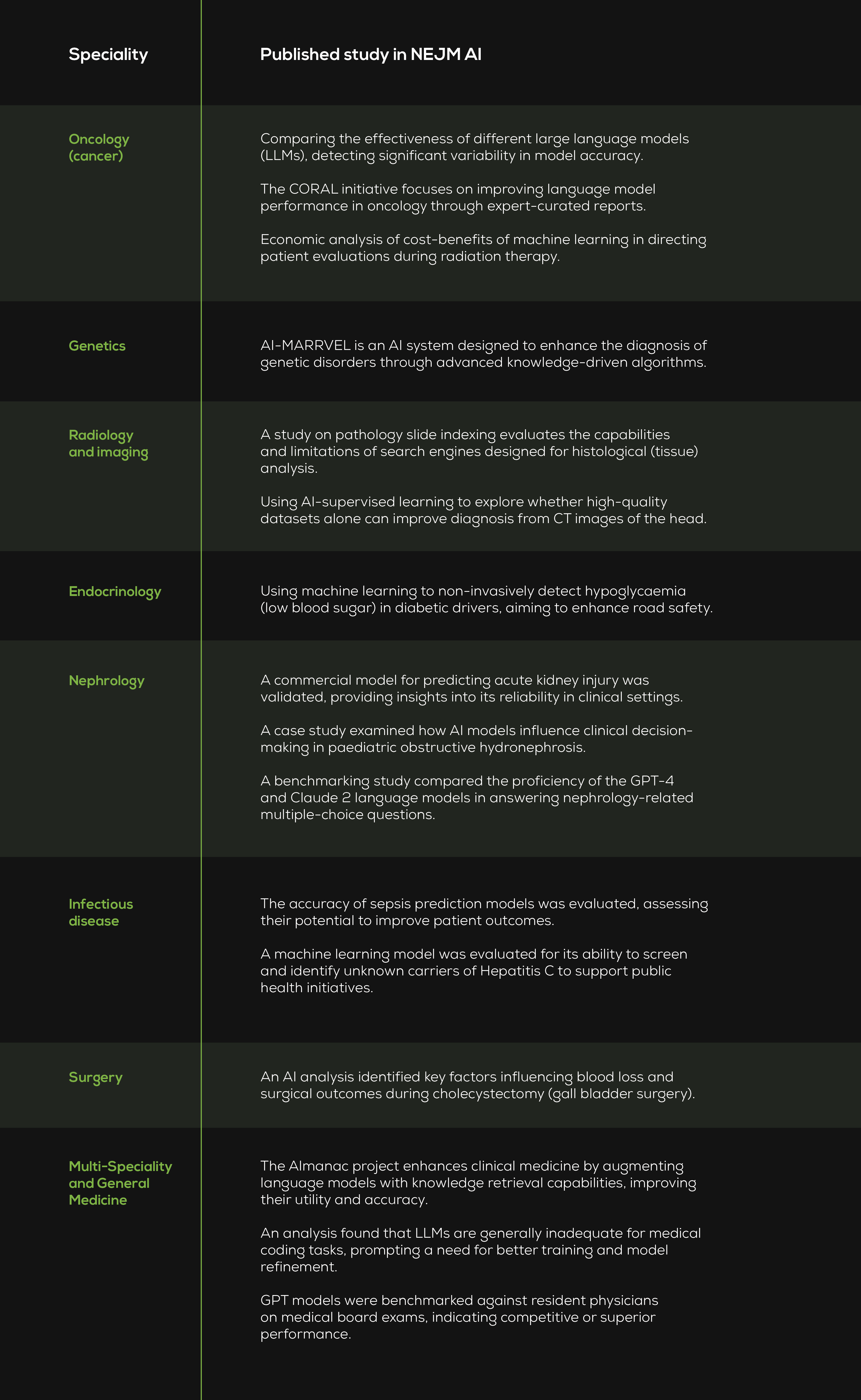
Table 1. NEJM AI is a new journal (parent publication: New England Journal of Medicine) with five published issues, all in 2024, containing about 30 papers. Its content offers a glimpse into the diverse applications of AI across different fields of medicine. Along with policy papers, studies and their clinical specialities include those below.
Get an email whenever we publish a new thought piece
If hypertension is common, measurable and treatable, why do so many patients still have uncontrolled blood pressure? Drug shortages, diagnostic challenges or a lack of treatment guidelines are not the
10.6 min read

In theory, hypertension should be easier to control in the insured population than in the country as a whole. Here are three reasons: Hypertension is a Prescribed Minimum Benefit (PMB).
7.3 min read
Meet our experts
Author

{kind=link}
More Insights
Focused Thought Pieces