You Ain’t Seen Nothing Yet
It’s astonishing how Large Language Models (LLMs) can do what was once only science fiction: understand and generate fluent, human-like text, art, music, video, computer code, and complex documents, with minimal input, to power robots, and more.
29 April 2024
8 min read
Image by Google’s Deepmind on pexels.com
Like the song by Bachman-Turner Overdrive (BTO) – number one on the Billboard and SA Singles Charts in 1974 – generative AI (like ChatGPT and others) has been an immediate hit. Also, a surprise. It’s astonishing how Large Language Models (LLMs) can do what was once only science fiction: understand and generate fluent, human-like text, art, music, video, computer code, and complex documents, with minimal input, to power robots, and more.

As in the song’s memorable, stuttering chorus “B-B-B-Baby, you just ain’t seen n-n-n-nothing yet,” more is coming, surprise or no surprise, and is likely to change almost every industry.
But, the AI-dominated future isn’t necessarily rosy. Here are two of several major concerns. First, in energy terms, AI is hugely less efficient than the human brain, requiring electricity consumption that’s not healthy for society or the planet. Second, the cost of massive data centres that host cloud and AI systems may limit use to elites, widening already dangerous disparities.

Encouragingly however, recent innovations in hardware and software suggest that wider availability of AI at lower cost and with less environmental damage might be possible.
Grok the new hardware
Nvidia supplies most of the computer chips powering AI. Global market dominance has propelled it to third most valuable company in the US – worth $2 trillion as of March 01, 2024).
Meanwhile, the startup Groq (grok – “understand” – is a neologism coined by Robert Heinlein in a 1961 novel) has introduced a novel hardware design – Language Processing Units (LPUs) customised for Large Language Models. These chips enable LLMs to run 3 to 18 times1 faster and twice as efficiently, making interactions with GPT and other LLMs more or less instantaneous.
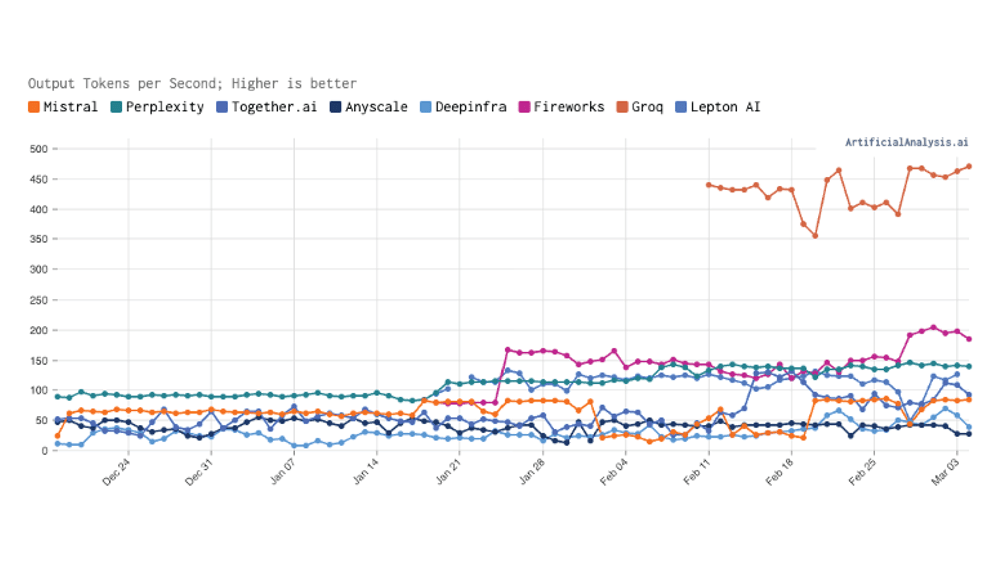
Image: https://artificialanalysis.ai showing Groq’s speed advantage. Tokens refer to the smallest units of data or text that an artificial intelligence system processes, such as words, characters, or subwords, for understanding and generating language.
Groq’s breakthrough chip design is described in a highly technical conference publication made more understandable with this analogy (thanks ChatGPT) …

Imagine a bustling city with roads (data pathways) and intersections (processors). This city is unique – designed to learn and adapt, much like a brain. However, as it grows, with more roads and intersections added to accommodate learning needs, traffic jams (data bottlenecks) become a problem. These jams slow down the city’s ability to learn and process information efficiently. The traditional approach involves building standard roads and intersections that, while functional, don’t communicate or synchronize well with each other, leading to unpredictable traffic flow and delays in processing information.
The Groq LPU chip design is like redesigning the city’s infrastructure with smart, software-defined roads and intersections. The system knows where every vehicle (data packet) is at any given moment and controls how and when it should move. All parts of the city communicate and synchronize, eliminating traffic jams and making information processing fast and efficient.
Management of traffic flow at intersections ensures no time is wasted at red lights when the road ahead is clear. Communication among processing elements means every piece of data knows exactly where and when to move, avoiding delays. The city’s highways are wide and designed to handle large traffic volumes without bottlenecks. The system anticipates and prevents congestion by spreading out vehicles across all available lanes and roads in a balanced way. When occasional issues arise, like a vehicle breaking down, rapid response teams quickly address the problems without disrupting overall flow.
By analogy, on the Groq chip, processing of vast amounts of data happens efficiently and reliably, paving the way for more advances in machine learning capabilities.
Revising the LLM – BitNet b1.58
Just like Nvidia’s dominance, the transformer model, since 2017, has been the fundamental design basis of LLMs (transformer is the “t” in GPT). But new ideas like the “1-bit LLM’ – BitNet b.158 – despite the lack of a hit name – are emerging that may deliver higher performance with less resources.
Here’s another explanation, in non-technical terms, and by analogy (thanks again to ChatGPT) …
Imagine a smart assistant trained to understand and generate human-like text. It uses a very complex recipe (the model) filled with specific settings or ingredients (model parameters) that helps it learn how to respond to questions, write stories, or translate languages. As this assistant becomes more knowledgeable and capable, the recipe becomes even more complex, requiring more energy and resources to use it effectively. This makes it expensive and slow, particularly when quick responses are needed.

BitNet b1.58 is a new type of smart assistant, built on a concept called a 1-bit LLM. It tweaks the traditional recipe in a way that drastically reduces its complexity without losing response quality. It does this by simplifying its list of ingredients to just three main types (-1, 0, and 1), making the recipe not only easier to follow but also much more efficient. This means it needs less energy to run and can work faster, making it eco-friendly and more accessible to a wider range of devices, even those not typically powerful enough to handle such complex tasks.
The magic behind this new assistant includes a technique known as “feature filtering,” which allows the assistant to ignore unnecessary information and focus only on what’s truly important for understanding and generating language. This is like reading a long article but only paying attention to the key points of interest. The assistant becomes even quicker (reducing latency, or the delay between asking a question and getting an answer), ensuring swift and relevant responses.
BitNet b.158 offers a way to implement AI tools that are cost-effective and energy-efficient and also fast and accessible on a range of devices, from powerful servers to smartphones. Eventually with a new name, hopefully.
Implications and future horizons
Nvidia’s success suggests Groq has a bright future. More hardware innovations like this, Moore’s law style, and better LLM design, like Google Gemini’s expanded concept windows, will raise performance and reduce energy cost per unit. We will then have a better chance for AI to be safely and equitably introduced, to help address complex challenges, from climate change to healthcare, education and space exploration.
It’ll be up to business and political leaders to decide how to align this technology to a happier future for humans and the planet. Good leadership is in short supply but in healthcare responsible voices are being heard, including the authors of February 2024 guidelines in NEJM and Nature Medicine. We’ll take a close look at them soon.
Listen to my AI-composed update to the BTO song is here. It won’t be a hit. Meanwhile we close with optimistic words from Jonathan Ross, CEO of Groq.
“Groq exists to eliminate the ‘haves and have-nots’ and to help everyone in the AI community thrive … It is … rewarding to have a third party validate that the LPU Inference Engine is the fastest option for running Large Language Models” … “speed is what turns developers’ ideas into business solutions and life-changing applications”.
Get an email whenever we publish a new thought piece
If hypertension is common, measurable and treatable, why do so many patients still have uncontrolled blood pressure? Drug shortages, diagnostic challenges or a lack of treatment guidelines are not the
10.6 min read

In theory, hypertension should be easier to control in the insured population than in the country as a whole. Here are three reasons: Hypertension is a Prescribed Minimum Benefit (PMB).
7.3 min read
Meet our experts
Author

More Insights
Focused Thought Pieces